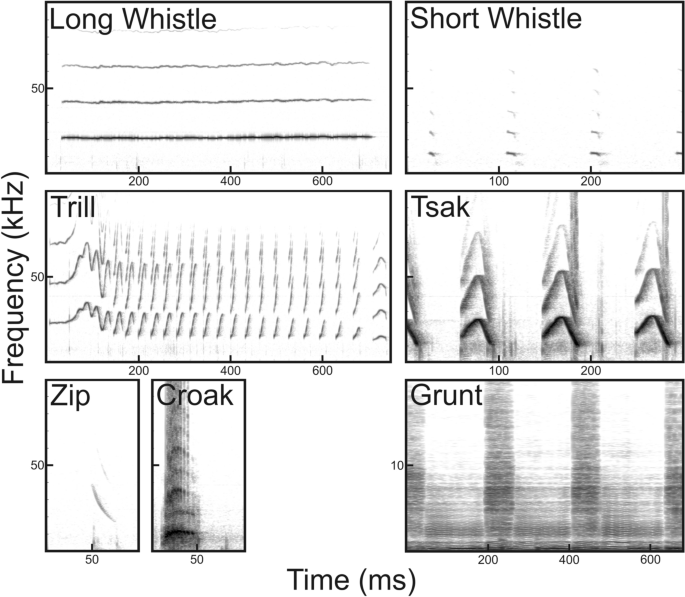
Utilizing DeepSqueak for automatic detection and classification of mammalian vocalizations: a case study on primate vocalizations Bioacoustic analyses of animal vocalizations are predominantly accomplished through manual scanning, a highly subjective and time-consuming process. Thus, validated automated analyses are needed that are usable for a variety of animal species and easy to handle by non-programing specialists. This study tested and validated whether DeepSqueak, a user-friendly software, developed for rodent ultrasonic vocalizations, can be generalized to automate the detection/segmentation, clustering and classification of high-frequency/ultrasonic vocalizations of a primate species. Our validation procedure showed that the trained detectors for vocalizations of the gray mouse lemur (Microcebus murinus) can deal with different call types, individual variation and different recording quality. Implementing additional filters drastically reduced noise signals (4225 events) and call fragments (637 events), resulting in 91% correct detections (Ntotal = 3040). Additionally, the detectors could be used to detect the vocalizations of an evolutionary closely related species, the Goodman’s mouse lemur (M. lehilahytsara). An integrated supervised classifier classified 93% of the 2683 calls correctly to the respective call type, and the unsupervised clustering model grouped the calls into clusters matching the published human-made categories. This study shows that DeepSqueak can be successfully utilized to detect, cluster and classify high-frequency/ultrasonic vocalizations of other taxa than rodents, and suggests a validation procedure usable to evaluate further bioacoustics software. Animal bioacoustics is a growing field in basic and applied research. One central research topic is the development of bioacoustic monitoring systems (e.g., Refs.1,2,3,4,5) to improve animal management by monitoring animal welfare, animal health, animal behavior and animal reproductive state (e.g., Refs.6,7,8,9,10,11,12) or to monitor animal abundance for animal conservation (e.g., Refs.13,14,15,16,17,18). In the last decades, animal bioacoustic research especially in the ultrasonic range has been largely limited by technical issues such as frequency characteristics of the microphone, sampling rates, working memory of the recorder or storage capacity. However, these technical hurdles have been overcome by recent technological advancement. Thus, today, researchers are able to record animal vocalizations, even in the ultrasonic range, 24 h per day for several days per week (e.g., Song Meter model SM4/SM4BAT-FS (Wildlife Acoustics Inc., Maynard, MA, USA), AURITA19). Therefore, today in animal vocalization research, bioacoustic analysis of vocal recordings is the limiting factor and not technical limitations of the recording.The traditional method used for screening vocal recordings is visual scanning and classification of vocalizations based on the sonogram20,21. However, manual scanning and classification are unfeasible for collecting thousands of vocalizations. Additionally, the success of this approach often depends on the knowledge and experience of the analyst21. Thus, we need new automatic analysis tools to speed up the screening of these large data streams, and to detect and classify call types independently from the experience of the human observer. Animal bioacoustics researchers have developed several detection systems for animal vocalizations using mathematical algorithms (e.g., Refs.3,4,11,22). Although the usage of these systems is widespread in specific subgroups of the bioacoustic community depending on the animal group of interest (e.g., PAMGuard in the marine mammal community22, Kaleidoscope in the bat community23, MUPET in the rodent community4), these rarely overcome the taxa boundaries so that they can be used by the whole bioacoustic community including small and large bodied terrestrial, aquatic mammals and birds. One reason is that animal vocalizations vary largely in the frequency range (from infrasound to ultrasound) and in their acoustic structure (harmonic to noisy calls), making it difficult to develop a general animal vocalization recognition system. Thus, most tools were designed for a specific animal species and/or vocalization types (e.g., birds1,24, rodents2,25, primates26,27,28,29,30,31, cetacea3,32,33, elephants34,35, pigs9,11,12, bats36,37). Another reason is that these programs are difficult to master for non-specialists because some of these tools require a fundamental understanding of bioacoustics and programing. Thus, software is needed which can be used for a wide variety of animal species and is easy to handle for non-specialists.In 2019, DeepSqueak25, a promising new software suited for automatic detection, classification and clustering of ultrasonic vocalizations (USV) was introduced to the animal bioacoustic community. While originally built with focus on ultrasonic mice and rat vocalizations ranging from 20 to 115 kHz, the DeepSqueak GUI (graphical user interface) is intuitive and parameters can be adjusted for other species without pre-required skills in programing. The core feature of DeepSqueak is its state of the art application of a machine-learning algorithm. The algorithm is similar to convolutional neural networks (CNN) used for automatic speech recognition systems such as Alexa, Siri or Cortana38,39. Using faster regional-convolutional neural networks (Faster-RCNN)40, DeepSqueak has an increased call detection rate, a reduction in the number of false positives, a reduction in analysis time compared to older detection software (such as Ultravox (Noldus, Wageneing, NL)5, MUPET4 or Xbat41). DeepSqueak allows multiple Faster-RCNN centered approaches for automatic USV detection. In addition, DeepSqueak has a GUI that enables users to conduct manual reviewing, editing and labeling of detection files. It also integrates supervised classification networks and unsupervised clustering models that can be trained and used for further analyses of data. Supervised classification networks can be trained based on detections labeled according to, for example, user pre-defined clusters (call types). In the unsupervised approach, these clusters are created based on frequency, shape parameters and duration of vocalizations either by the k-means or by dynamic time-warping (experimental algorithm) method. The supervised approach has the advantage to automate, and therefore speed up the identification of the vocal repertoire of a species based on information from previously described call categories27. The unsupervised model has a less controllable outcome but is unbiased to priori assumptions of the observer.In the present study, we tested whether DeepSqueak can be utilized to analyze high-frequency to ultrasonic vocalizations in a primate species, the gray mouse lemur (Microcebus murinus), and whether the detector’s ability is sufficiently general to be used for other mouse lemur species. Mouse lemurs are nocturnal strepsirrhine primates endemic to the dry forest of Madagascar42. They are able to produce calls and to perceive acoustic information from audible to ultrasonic frequency range (auditory frequency range: 800 Hz to 50 kHz43,44; voice production range: 400 Hz to 30 kHz of the fundamental frequency45,46,47). The best studied species is the gray mouse lemur for which to date ten call types are described (e.g., Refs.48,49,50). Seven call types (Grunts, Croaks, Tsaks, Long whistles, Short whistles, Zips and Trills, Fig. 1) are typical for the adult vocal repertoire. Thereby, Grunts and Croaks are low-frequency noisy calls, whereas Tsaks, Short whistles, Long whistles, Trills and Zips are harmonic calls uttered in the high-frequency to ultrasonic range and differ in the contour of the fundamental frequency. Tsaks and Short whistles are uttered in series of variable duration during agonistic or alarm situations, whereas Long whistles, Trills and Zips are uttered singly. Long whistles are uttered during sleeping group formation and mating mainly by females. Trill is the acoustically most complex call consisting of several syllables, uttered during various social interactions (e.g., mating51, mother-infant reunions52 and sleeping group formation53). Zips are soft calls often associated with Trills, whose social function remains uncertain. Mouse lemur calls carry indexical cues encoding kinship54,55, familiarity (dialects56), individual identity47,57 and hormonal status58.Figure 1Vocal repertoire of the gray mouse lemur (M. murinus) based on Zimmermann (2018)49,50.The aim of our study was to test whether DeepSqueak developed for mouse and rat vocalizations can be utilized to detect, cluster and classify vocalizations of a primate, the gray mouse lemur, uttered in the high-frequency to ultrasonic range. Additionally, we investigated whether detectors trained for M. murinus can also be used to detect vocalizations of a closely related mouse lemur species, M. lehilahytsara. Defining call types through visual inspection is especially difficult when differences among call types are not discrete but continuous59,60 (e.g., transitions from Short whistle to Tsak). Thus, we tested whether supervised classifier can be used to objectively label mouse lemur vocalization. Additionally, we explored to which extent clusters of mouse lemur vocalization defined by the algorithm (unsupervised model) match the already established human-based call type categories reported in the literature48,49,50.The data sets used in this study originated from the sound archives of the Institute of Zoology, University of Veterinary Medicine Hannover, Germany storing sound recordings from the captive self-sustaining mouse lemur breeding colony of the institute (license: AZ 33. 12-42502-04-14/1454; AZ33. 19-42502-11A117). All recordings were made in a sound-attenuated room at the Institute of Zoology. The sound recordings were obtained during various independent behavioral studies (e.g., social encounter paradigm, playback study43,47) conducted between 2003 and 2012 using recording equipment sensitive to the high-frequency to ultrasonic range (see Supplementary Table S1 for details on the experimental paradigms and recording equipment). We used only vocalizations from adult animals, since these vocalizations are well studied (e.g., Refs.49,50). Details on the acoustic parameters of the studied call types can be found in Supplementary Tables S2 and S3.For the training data set, we used 2123 vocalizations belonging to the five most common call types to represent the high-frequency/ultrasonic adult vocal repertoire49,50. The chosen types range from short to long calls, from unmodulated to highly modulated calls, as well as weak to strong amplitude vocalizations providing a great insight into the general performance of DeepSqueak to identify diverse syllable structures as well as detection performance on amplitude variation rich syllable regions and calls. The training data set was obtained from 27 preselected recording sessions and recorded from 24 individuals or groups (in the case where the sender could not be reliably determined, because the observer could not hear and spatially locate the sender of the ultrasonic call). The recording sessions originated from the social encounter, the handling and the mother-infant reunion paradigm (Supplementary Table S1) and included different recording qualities to increase the robustness of the detector against individual variation in the call structure and differences in the recording quality. To validate the detectors, we used the standardized and experimental data sets (evaluation data sets; Table 1).Table 1 Description of the training, standardized and experimental data sets used in this study. The table represents the number of calls for each call type included in the respective data set. Ncalls number of calls, NInd/groups number of individuals or groups from which the calls were emitted.The standardized data sets were used to test for the robustness of individual variation and recording quality (Fig. 2: 1b; for detailed information, see Supplementary Methods: Additional information on the preparation of the standardized data sets). The term standardized refers to the fact that we combined single vocalizations (not used in the training data set) of the sound archive to a single audio file to maximize the number of different individuals/groups for the five trained call types (Long whistle, Trill, Zip, Short whistle, Tsak) and to test four different recording quality scenarios: good-quality, clipped, low-amplitude, overlaid calls (Table 1; for the definition of the quality scenarios, see Supplementary Methods: Additional information on the preparation of the standardized data sets). Whereas Long whistles, Trills and Zips are emitted singly, Tsaks and Short whistles are emitted in a series, ranging from five up to multiple hundred calls. To represent the natural structure of Tsaks and Short Whistles three continuous calls of a series were selected (as a compromise between real life occurrence and data evaluation) to test whether the detectors could detect the single calls within a series, which are separated by a short intercall-interval (< 200 ms)61. For each call type, the single calls/series were combined to a single audio file to test whether performance was consistent across different call types, using PRAAT (www.praat.org)62 combined with GSUPraatTool 1.963 (for detailed information, see Supplementary Methods: Additional information on the preparation of the standardized data sets). As original audio data contained intercall-intervals of background noise between calls, we added three seconds of white noise with an amplitude of 28 db between two consecutive calls that were combined into standardized data sets to simulate real life noise. For the good-quality standardized data set, 50 single calls/series were combined for each call type. For the clipped, low-amplitude and overlaid standardized data sets, ten single calls/series were used for each call type (Table 1). For Zips, there were only data available for the good-quality standardized data set.Figure 2Scheme illustrating the three different models trained and evaluated in this study. Model (1) Detection task: (1a) Training the detectors using image-based CNN with the training data. Evaluation of the trained detectors with (1b) the standardized data a
https://www.nature.com/articles/s41598-021-03941-1
Utilizing DeepSqueak for automatic detection and classification of mammalian vocalizations: a case study on primate vocalizations